AWS RDS For PostgreSQL 성능 최적화
사내에서 개발중인 서비스는 PostgreSQL DB를 사용중이다. 아직 베타를 출시한 것은 아니지만 쿼리 하나 날리는데 20초가 걸리는 경우가 있었다. 백엔드 개발자이지만 DB 전문가는 아니라 쿼리를 어떻게 더 튜닝해야할지 몰랐다. 먼저 RDS 인스턴스를 변경해보았다.
1. RDS 인스턴스 db.t3.medium -> db.mg.large 로 변경

기존에 사용하던 DB사양은 위와 같았다. 속도가 느리기도 하고 DB 성능을 높일 때가 된 것 같아 아래와 같은 사양으로 변경하였다.

2. RDS Parameter 변경
RDS -> 데이터베이스 -> 데이터베이스명 -> 구성을 보면 파라미터 그룹이 있다. 그걸 클릭하면 pg_setting에 있던 값들이 나온다. DB에서 update문을 사용하여 직접 수정하는 게 아니라 파라미터 그룹에서 수정하면 된다.
3. 파라미터 그룹 수정
3-1) max_connection

서비스를 사용할 최대 접속 갯수보다 20% 정도의 여분을 가지고 있으면 충분하다. 나는 이전에 이미 수정해둔 상태다.
3-2) shared_buffers

메모리의 15% 여유분을 두고 값을 넣었다. 계산공식은 아래와 같다.
-- 157286
select (15*8*1024*1024 /100)/8;15 는 15%를 뜻하고, 8은 8GB의 메모리를 뜻한다. 1024 * 1024는 GB to KB를 계산하는 공식이다. 마지막의 8은 8KB이다.
또는 아래와 같이 계산해도 좋다. 앞서서 pg_bufferdcache를 설치하자.
postgres=> create extension pg_buffercache ;
CREATE EXTENSION
설치가 되어있다면, 아래의 쿼리를 실행하여 테이블 대비 캐시 비율을 확인한다.
select c.relname as relname ,
pg_size_pretty(count(*) * 8192) as buffered ,
round(100.0 * count(*) / ( select setting from pg_settings where name='shared_buffers')::integer,1) as buffer_percent ,
round(100.0*count(*)*8192 / pg_table_size(c.oid),1) as percent_of_relation
from pg_class c inner join pg_buffercache b
on b.relfilenode = c.relfilenode inner join pg_database d
on ( b.reldatabase =d.oid and d.datname =current_database())
group by c.oid,c.relname
order by 3 desc;
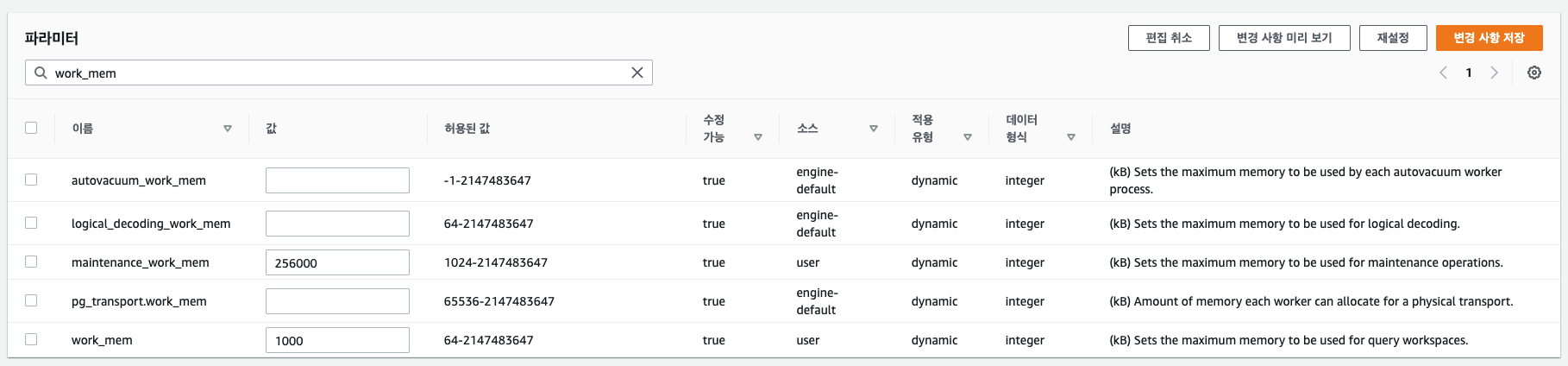
3-3) work_mem
work_mem은 질의 수행 시 사용하는 메모리의 크기이므로 정렬 속도에 영향을 준다. 접속할 때마다 할당되므로 max_connection을 고려하여 잡아야 한다. maintenance_work_mem도 설정해야하는데 이것은 vacuum 작업에서 사용한다.
3-4 effective_cache_size
데이터 캐싱에 사용할 수 있는 양으로 시스템 전체 메모리의 50~70%로 설정한다.
'DBMS > PostgreSQL' 카테고리의 다른 글
| [PostgreSQL] 데이터가 있으면 UPDATE / 데이터가 없으면 INSERT (0) | 2023.02.20 |
|---|---|
| [PostgreSQL] DB 파티셔닝(Partitioning) 정의 및 예제 (0) | 2023.02.09 |
| [PostgreSQL] 공간 인덱스 활용 (0) | 2023.02.07 |
| [PostgreSQL] 뷰(View) 테이블 생성 및 제어 (0) | 2023.01.27 |
| [PostgreSQL] 특정 문자열 개수 구하기 (0) | 2023.01.19 |

최근댓글